A Tale Of Concurrency: Partitioning Data Between Processes
So I had just finished writing this feature. I was confident it’d work - after all I had a good level of tests around it. It sounded like yet another successful deployment.
One week in and something starts breaking. It was hard to track down but at the end I realised it was caused by having concurrent processes running in parallel.
That’s what happened in a recent production release at our current client. It was a very interesting problem to track down and solve and I’ll do my best to explain and walk you through it here.
What we were trying to achieve
I’ll try not to go into many details here as to how the feature works but here is the gist of it:
A user from the staff can select from a range of criteria to create a “List” that is used to match users against the database. These criteria are serialized to the database in this list object to allow for further processing.
When required, the staff can choose to mail the users resulting from that list. To get the set of users, the system de-serializes the criteria contained in the list, builds a SQL query and runs it against the database.
Constraints
These lists are contained in something called a “Push”. That’s just a concept that identifies that a set of lists and emails belong to a specific theme, say, ‘Kitty lovers’.
It’s a powerful concept though because its single most important rule is that a user should never receive more than one email within the same “Push”.
For example, take a look at the image below, which represents a Push in progress. Let U be the universe of all users in the database. L are users returned by a List within a given Push. R is the set of users that have already received an email from that Push.
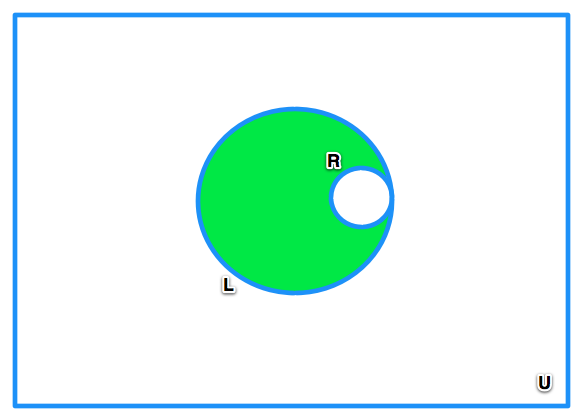
Based on the rules I explained above, the green area then represents users we can still send emails to.
Content testing
With all the basic concepts in place, let’s pretend we are actually creating a Push for the ‘Kitty Lovers’. I am organizing a kitty expo at my house and I want to invite everyone that lives within 50km of Sydney, Australia - see the list specification going on here?
Let’s say this list gives us 25000 users. My house’s better be huge.
Simple enough, but I actually have 2 emails to send. They have different content, say 2 different pictures, and before I invite everyone, I want to test which email works best by sending them both to a subset of the list - make it a thousand random users each. After all, I want my event to be a huge success.
After I decide which email is best - the system tracks opens, clicks, etc… - I want to send it to the rest of the list, which is to say every user that has not received an email from this Push yet.
Offloading work, the problem begins
Due to certain architecture and performance requirements the unit of code that runs the list’s criteria against the database, gets the user ids and sends the email, is sent to a job queue to be later executed by a background process.
In development and staging we only ever had a single background process running so all was well. The code was basically executed sequentially.
In production however, we can - and usually have - several background workers picking up jobs from the queue. And that’s when the bug happened:
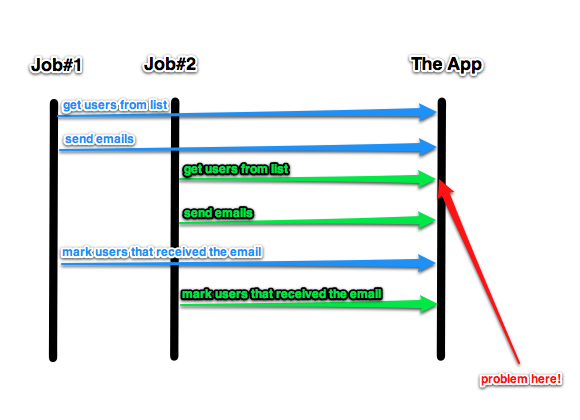
As you can see in the above image, given you have 2 jobs running in parallel, Job#1 selects the users from the list, starts sending some emails and in the meantime Job#2 comes along, selects roughly the same users and starts doing the same before Job#1 has had enough time to mark those users as having received the email already. Bam! Some users will receive duplicates!
The solution
I spent a lot of time literally staring at my laptop’s screen thinking about how to solve this issue. Locking the table? Nah… that would render having multiple workers useless.
What I really needed was a way to partition the data between jobs so as to avoid different jobs from dealing with the same set of users.
My next thought was to run the query once beforehand to sort the list of user ids, split it in groups equal to the number of jobs and work out the id ranges each job should deal with.
Although this solution would work, it would add the extra step of running the query once before actually running the jobs. That did not make me happy.
That’s when I started thinking about a metaphor that helped me come up with this insight: a Hash Table. If you ever implemented one you can see that the buckets in a hash table could be related to the jobs we have running.
I basically wanted different users to go to different buckets. Think hash functions. Think modulus.
To follow this approach I changed my code so that each job would be assigned an id, starting at 0, up to (number_of_jobs - 1). Then, when putting the jobs in the queue I would provide 2 extra arguments: the current job id and the total number of jobs.
Upon execution, the job would use these extra arguments to modify the query, adding an extra field to the select clause:
SELECT ..., MOD(users.id, number_of_jobs) AS modulus...
And it would also append an extra filter to the where clause:
WHERE ... AND modulus = current_job_id
That way, users would be spread as evenly as possible between jobs and no single user would be processed by more than one job.
For example: If we had 2 jobs, ids 0 and 1 and a list of 10 users with ids from 0 to 10, this would be the users distribution between jobs:
user_id:0 - processed by job_id:0 (given by 0 mod 2)
user_id:1 - processed by job_id:1 (given by 1 mod 2)
user_id:2 - processed by job_id:0 (given by 2 mod 2)
user_id:3 - processed by job_id:1 (given by 3 mod 2)
user_id:4 - processed by job_id:0 (given by 4 mod 2)
user_id:5 - processed by job_id:1 (given by 5 mod 2)
user_id:6 - processed by job_id:0 (given by 6 mod 2)
user_id:7 - processed by job_id:1 (given by 7 mod 2)
user_id:8 - processed by job_id:0 (given by 8 mod 2)
user_id:9 - processed by job_id:1 (given by 9 mod 2)
user_id:10 - processed by job_id:0 (given by 10 mod 2)
A simple, elegant solution for a tricky problem. One that I’m finally happy about.
If you made it to here, I appreciate your patience and hope you enjoyed the read ;)